
Automate dataset collection with
Peacock Data
Peacock Data searches the world wide web, crawls and analyzes the semantic content of pages, and builds a specialized dataset of relevant online content for your application.
AI-Enhanced Web Crawling
Targeted Web Crawling
Crawl the web based on search queries or specific URLs to collect data for.
Semantic Filtering
Smart content extraction and filtering ensure your crawl datasets only include relevant content, saving time and money.
Captcha Bypass
Automatic captcha detection and resolution help to procure the highest quality data from your crawl processes.
Scheduled Execution
Schedule crawl subjects to run only once, or on a regular schedule to ensure your data stays current.

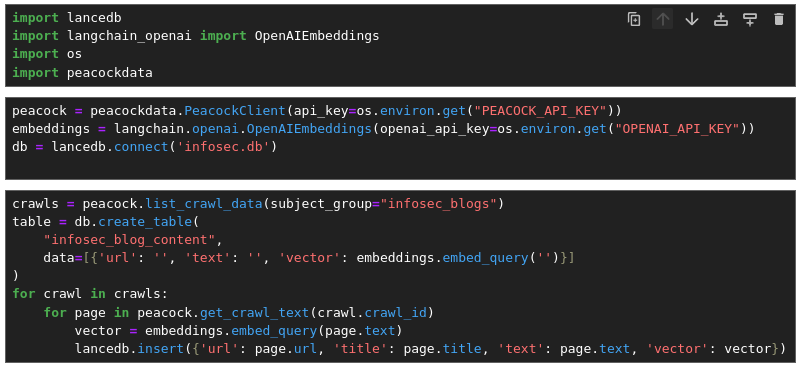
Integrated directly with Python
Import the peacockdata package to schedule and load your crawl datasets straight from your python environment.
Crawl Data Notebooks
Build peacockdata right into your pipelines to analyze web crawl data.
- Download crawl artifacts
- Replay web pages
- Run SQL queries over crawl metadata
Use your crawl data to build a vector database for RAG applications, fine tune an LLM, or monitor the web for events.

Find a plan that's right for you
Get started with a free plan to experiment with the API and start testing out your ideas. Scale up at low cost as you grow.
- 24 hours of crawling per month
- 10 GiB of crawl data storage
- Unlimited captcha bypass
- Up to 1,000 crawl subjects
- Crawl at $0.003/minute
- Store data at $0.025/GiB
- Up to 1,000,000 crawl subjects
- Priority crawl scheduling
- Bring your own S3 storage
- Unload to Apache Iceberg
- Unload to Snowflake
- Unlimited Crawl Subjects
Get started with Peacock Data
It only takes a few minutes to get your first crawl dataset going.